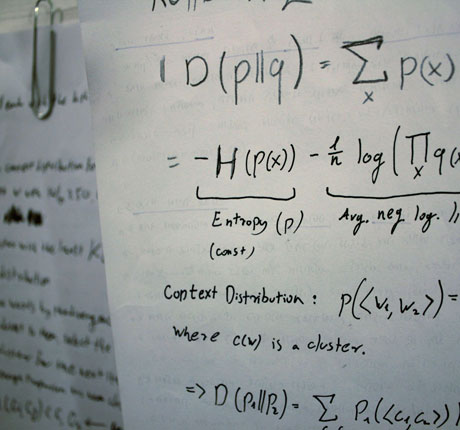Constructing lexical categories without knowing the language
Syntactic is an automated lexical categorizer, built for a Learnability/Machine Learning course in Tel Aviv University.
The program reads huge arbitrary texts in any language and organizes them into lexical categories, without knowing a thing about the language (save for punctuation marks). The project is now open source.
Context is Everything
The program works by reading a word and its surrounding words (its context) in a sentence. If two words are used in the same sort of context, suppose “a banjo string” and “a lyre string”, then the program guesses “banjo” and “lyre” belong in the same category. Categories are formed through time based on the strongest correlation between words, using a common method in Machine Learning called Clustering.
Visual Intelligence
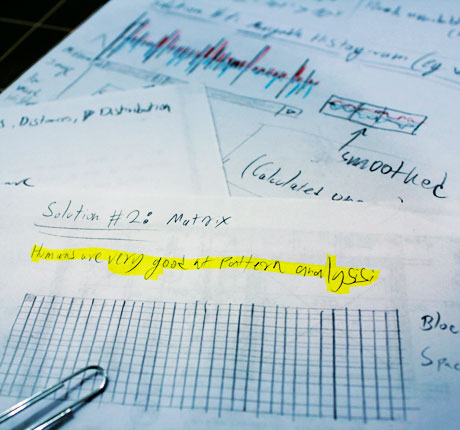
Humans are much better at recognizing patterns than machines are. That claim is the basis to many human based computation games (McGill’s Phylo, University of Washington’s Foldit, and the life-saving ReCaptcha project), and this visualization relies on that claim as well. The program uses a statistical method to compare between two pieces of information about words. The method, called KLIC, returns a good score if dataset A projects itself well onto dataset B, even if the opposite is not true. This notion led me to believe that the cues that help the method construct a match are visually accessible.
See the KLIC
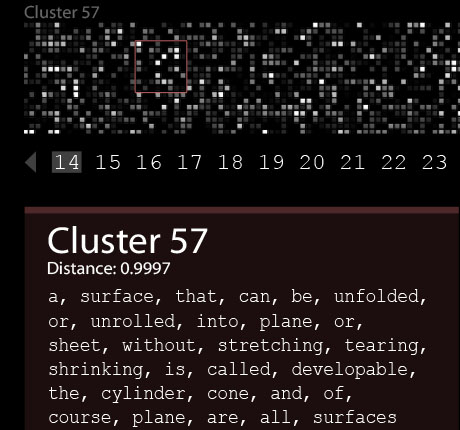
In the visualization, people can browse words, see their data distribution and compare it to the data distribution of target clusters. Each parameter in the context data is displayed using a single square on a board, lit with its relative amount. If every feature (non-black square) in the word is present in the cluster, then the distance is expected to be quite close. However, if even one feature is present in the word but absent in the cluster, the distance between them gets bigger.
By looking at the pattern formed by the word and searching for it in the cluster, humans can quickly get a good estimation on the distance. On a strong machine, this computation may take up to 4 minutes per word. In a quarter of that time, Humans may be able to mark dominant candidates, thus simplifying the computation significantly. It shouldn’t be too unintuitive to understand that – after all, humans invented syntactic categories.
Credit
Program Code: Omer Shapira
Visualization Design: Omer Shapira
Visualization Authoring: Bar Vinograd and Omer Shapira
Academic Supervisor: Dr. Roni Katzir
Syntactic is based on an algorithm described by Alexander Clark.